找到
29
篇与
刘纪彤
相关的结果
- 第 2 页
-
 【计算机考研(408)- 数据结构】栈和队列 栈和队列 栈 一种只允许在一段进行插入或删除操作的[[线性表#什么是线性表|线性表]]。 栈的定义 栈(Stack)是一种只允许在一端进行插入或者删除操作的线性表。它也是一种线性表,但是它限制了其插入和删除操作,相关概念: 栈顶:线性表允许进行插入和删除操作的那一段。 栈底:固定的,不允许进行插入和删除操作的另一端 空栈:没有任何元素的空表 对于栈这个数据结构,可以概括为它是一种进行后进先出操作的线性表(Last In First Out,LIFO)。 栈的基本操作 栈的基本操作可以说和线性表的操作大差不差,同时结合栈自身的操作特性得到其基本操作:初始化一个栈、判断栈是否为空、入栈、出栈、获取栈顶操作、销毁栈,函数名就不多说了,写了这么多一定能写出来的。 栈的数学公式(卡特兰数) :当n个不同元素入栈的时候,出栈元素不同排列个数为$\frac{1}{n+1} C^n_{2n}$ ,我也不知道哪来的,记住! 栈的顺序存储结构 既然栈是一种线性表,那么它必然有两种存储方式:顺序存储/链式存储。 顺序栈的实现 栈的顺序存储结构也称之为顺序栈,他利用地址连续的存储单元存放自栈底到栈顶的数据元素,同时也会附设置值一个栈顶(top)指针来指示当前栈顶元素的位置。 栈的顺序存储结构可以用代码描述为: #define MaxSize 50 //栈中最大的个数 tyepdef strcut{ ElemType data[MaxSize];//栈中元素 int top;//栈顶指针 }SqStack;在这里: 栈顶指针:S.top 初始时设置为-1,栈顶元素S.data[s.top]; 入栈:判断是否已满,指针+1,再把值赋值给栈顶。 出栈:非空时,先取元素,再-1,同时返回该元素。 判空操作:S.top\=\=-1; 判满操作:S.top\=\=MaxSize-1; 栈的长度:S.top+1; 当然如果栈顶指针初始值时0的时候,只需要在入栈时,先赋值,再指针加一,出栈时先-1,再返回值,那么栈空和栈满操作都+1就可以了,栈的长度也就是S.top了。 在严蔚敏的数据结构中会出现S.top和S.base一起出现在栈中,这种情况下判空操作就变为S.top\=\=S.base,当然如果是栈满就可以用S.top-S.base>=S.stacksize来判断。 顺序栈的一些基本操作 下面所有方法以初始栈顶指针为-1为例: 初始化: void InitStack(SqStack &s);{ s.top=1; }判空: bool StackEmpty(SqStack s){ if(s.top==-1) return true;//空 else return false;//不空 }入栈 bool Push(SqStack &s,Elemtype x){ if(s.top==MaxSize-1) return false;//满 s.top+=1//指针先+1 s.data[s.top]=x;//再赋值 /* 书中++s.top也代表着先自增s.top指针再取值 */ return true; }出栈 bool Pop(SqStack &s,ElemType &x){ if(StackEmpty(s)) return false;//判断是否为空栈 x=s.data[s.top];/先出栈 s.top-=1;//再减一 /*书中s.top--同理*/ return true; }获取栈顶元素 bool GetTop(SqStack s,ElemType &x){ if(StackEmpty(s)) return false;//空 x=s.data[s.top]; return true; }入栈/出栈操作要注意s.top指针是从-1开始还是从0开始。共享栈 共享栈是指两个栈共享一块数组空间,那么根据栈的特性,很容易想到这块空间应当是栈底在这个数组空间两端,栈顶相向而行。 设置数组有MaxSize个元素,也就是说这个数组的有效下标从0到MaxSize-1,意味着呢,top0\=\=-1时代表着0号栈为空,top1\=\=MaxSize代表1号栈为空,如果top1-top0 \=\= 1的时候代表栈满,0号栈的操作和上面的类似,1号栈与其正好反过来 共享栈优点就是两个栈空间可以相互调节。 栈的链式存储结构 代码描述如下: typedef struct LinkNode{ ElemType data; struct LinkNode *next; }LiStack;简直就是跟单链表一个样,没错就是一个样子的。 我们可以设置一个head结点指向链表头结点,以后无论什么操作,都限定只能对表头进行操作,这样也体现了栈的后进先出的特性。 队列 队列(Queue)是只允许在一端进行插入,在另一端删除的线性表 队列的定义 队列(Queue)是只允许在一端进行插入,在另一端删除的线性表。它也是一种线性表,但是它限制了其插入和删除操作,相关概念: 队头 :允许删除的一端,又叫队首 队尾: 允许插入的一端 空队列:不含任何元素的空表 对于队列这个数据结构,可以概括为它是一种进行先进先出操作的线性表(First In First Out,FIFO)。 队列的基本操作 队列的基本操作可以说和线性表的操作大差不差,同时结合队列自身的操作特性得到其基本操作:初始化一个队列、判断队列是否为空、入队、出队、获取队头元素、销毁队列,函数名就不多说了,写了这么多一定能写出来的。 队列的顺序存储结构 他利用地址连续的存储单元存放自队头到队尾的数据元素,同时也会设置一个队头(front)指针来指示队头元素位置,一个队尾(rear)指针来指示当前队尾元素(也有的教材指向队尾的下一个位置)位置。 #define MaxSize 50 //队列中最大的个数 typedef struct{ ElemType data[MaxSize];//队列中元素 int front;//队头指针 int rear;//队尾指针 }SqQueue;这里: 队头指针:S.front 初始时设置为0,队头元素S.data[s.front]; 队尾指针:S.rear 初始时设置为0,队尾 元素S.data[s.rear]; 入队:判断是否已满,先把值送到队尾元素,再+1。 出队:非空时,先取元素,再+1,同时返回该元素。 判空操作:S.front\=\=S.rear; 判满操作:S.rear\=\=MaxSize; 队列长度:S.rear-S.front; 当然如果队尾指针初始值是-1的时候就要另行再论了,他可能需要先+1再赋值。这个需要自行判断。顺序队列的一些基本操作 初始化: void InitQueue(SqQueue &q){ q.front=0; q.rear=0; }判空: bool QueueEmpty(SqQueue q){ if(q.front==q.rear) return true;//空 else return false;//不空 }入队: bool EnQueue(SqQueue &q,ElemType x){ if(q.rear==MaxSize) return false;//满 q.data[q.rear]=x;//先赋值 q.rear+=1;//再指针+1 return true; }出队: bool DeQueue(SqQueue &q,ElemType &x){ if(QueueEmpty(q)) return false;//判断是否为空队列 x=q.data[q.front];//先出队 q.front+=1;//再+1 return true; }获取队头元素: bool GetHead(SqQueue q,ElemType &x){ if(QueueEmpty(q)) return false;//空 x=q.data[q.front]; return true; }针对判断是否满的操作,有这样一个疑问,q.rear==MaxSize代表着队列满吗?答案是不一定。如下面的图示。md1e9aqd.png图片 本图d中虽然只有一个元素,但是q.rear\=\=MaxSize,这时入队出现了上溢,但这种溢出不是真正的溢出,我们仍可以存放元素,所以为了解决这个问题,引入了[[栈和队列#循环队列|循环队列]]的概念。循环队列 为了解决提到的假溢出问题,提高存储空间的利用率,我们把顺序队列臆想成为一个环形结构。当队首指针Q.front==Maxsize-1后再前进一个位置到达0,这种操作可以用模运算,也就是Q.front=(Q.front+1)%Maxsize来表示。 循环队列的一些基本操作: 判空与之前一样,还是Q.front==Q.rear。 入队: bool EnQueue(SqQueue &q,ElemType x){ if((q.rear+1)%MaxSize==q.front) return false;//满 q.data[q.rear]=x;//先赋值 q.rear=(q.rear+1)%MaxSize;//再指针+1 return true; }出队: bool DeQueue(SqQueue &q,ElemType &x){ if(QueueEmpty(q)) return false;//判断是否为空队列 x=q.data[q.front];//先出队 q.front=(q.front+1)%MaxSize;//再+1 return true; }补充:区分队空还是队满的三种处理方式: 牺牲一个单元来区分队空或者队满。入队时少用一个单元,约定以队首指针在队尾指针的下一个位置时尾队满,也就是(Q.rear+1)%MaxSize==Q.front代表队满,Q.front==Q.rear代表队空。 增加size数据成员变量,入队时size++,出队时size--,size==0时队空,size==MaxSize时队满。两种情况都满足Q.front==Q.rear。 增设一个标志位,如果删除成功就置0,插入成功就置1。如果Q.front==Q.rear且标志位为0代表队空,标志位为1代表队满。队列的链式存储结构 队列的链式表示又称为链式队列。他是一个同时具有队首指针和队尾指针的单链表,队首指针指向队头结点,队尾指针指向队尾结点。接下来我只写代码,就不多赘述了。 定义: typedef struct LinkNode{ ElemType data; struct LinkNode *next; }LinkNode;//链表结点 typedef struct{ LinkNode *front,*rear; }LinkQueue;//链式队列创建队列: void InitQueue(LinkQueue &q){ q.front=q.rear=(LinkNode *)malloc(sizeof(LinkNode));//建立一个头结点 q.front->next=NULL; }判空 bool QueueEmpty(LinkQueue q){ if(q.front==q.rear) return true;//空 else return false;//不空 }入队: bool EnQueue(LinkQueue &q,ElemType x){ LinkNode *s=(LinkNode *)malloc(sizeof(LinkNode));//新建一个结点 s->data=x;//赋值 s->next=NULL;//新结点的next指向NULL q.rear->next=s;//将新结点接到队尾 q.rear=s;//更新队尾指针 return true; }出队: bool DeQueue(LinkQueue &q,ElemType &x){ if(QueueEmpty(q)) return false;//判断是否为空队列 LinkNode *p=q.front->next;//指向队头结点 x=p->data;//先出队 q.front->next=p->next;//将队头结点的next指向下一个结点 if(q.rear==p) q.rear=q.front;//如果出队的是队尾结点,更新队尾指针 free(p);//释放队头结点 return true; }双端队列 双端队列:只允许从两端插入、两端删除的线性表 双端队列的定义 双端队列:只允许从两端插入、两端删除的线性表 针对双端队列的不同应用场景,又分为以下: 输入受限的双端队列:只允许从一端插入、两端删除的线性表 输出受限的双端队列:只允许从两端插入、一端删除的线性表 栈和队列的应用及考点 罗列几个以后可能会考到的考点,慢慢补 栈的括号匹配 栈的表达式求值 栈在递归中的应用 队列在层次遍历中的作用 队列在操作系统的应用 双端队列的输出序列问题
【计算机考研(408)- 数据结构】栈和队列 栈和队列 栈 一种只允许在一段进行插入或删除操作的[[线性表#什么是线性表|线性表]]。 栈的定义 栈(Stack)是一种只允许在一端进行插入或者删除操作的线性表。它也是一种线性表,但是它限制了其插入和删除操作,相关概念: 栈顶:线性表允许进行插入和删除操作的那一段。 栈底:固定的,不允许进行插入和删除操作的另一端 空栈:没有任何元素的空表 对于栈这个数据结构,可以概括为它是一种进行后进先出操作的线性表(Last In First Out,LIFO)。 栈的基本操作 栈的基本操作可以说和线性表的操作大差不差,同时结合栈自身的操作特性得到其基本操作:初始化一个栈、判断栈是否为空、入栈、出栈、获取栈顶操作、销毁栈,函数名就不多说了,写了这么多一定能写出来的。 栈的数学公式(卡特兰数) :当n个不同元素入栈的时候,出栈元素不同排列个数为$\frac{1}{n+1} C^n_{2n}$ ,我也不知道哪来的,记住! 栈的顺序存储结构 既然栈是一种线性表,那么它必然有两种存储方式:顺序存储/链式存储。 顺序栈的实现 栈的顺序存储结构也称之为顺序栈,他利用地址连续的存储单元存放自栈底到栈顶的数据元素,同时也会附设置值一个栈顶(top)指针来指示当前栈顶元素的位置。 栈的顺序存储结构可以用代码描述为: #define MaxSize 50 //栈中最大的个数 tyepdef strcut{ ElemType data[MaxSize];//栈中元素 int top;//栈顶指针 }SqStack;在这里: 栈顶指针:S.top 初始时设置为-1,栈顶元素S.data[s.top]; 入栈:判断是否已满,指针+1,再把值赋值给栈顶。 出栈:非空时,先取元素,再-1,同时返回该元素。 判空操作:S.top\=\=-1; 判满操作:S.top\=\=MaxSize-1; 栈的长度:S.top+1; 当然如果栈顶指针初始值时0的时候,只需要在入栈时,先赋值,再指针加一,出栈时先-1,再返回值,那么栈空和栈满操作都+1就可以了,栈的长度也就是S.top了。 在严蔚敏的数据结构中会出现S.top和S.base一起出现在栈中,这种情况下判空操作就变为S.top\=\=S.base,当然如果是栈满就可以用S.top-S.base>=S.stacksize来判断。 顺序栈的一些基本操作 下面所有方法以初始栈顶指针为-1为例: 初始化: void InitStack(SqStack &s);{ s.top=1; }判空: bool StackEmpty(SqStack s){ if(s.top==-1) return true;//空 else return false;//不空 }入栈 bool Push(SqStack &s,Elemtype x){ if(s.top==MaxSize-1) return false;//满 s.top+=1//指针先+1 s.data[s.top]=x;//再赋值 /* 书中++s.top也代表着先自增s.top指针再取值 */ return true; }出栈 bool Pop(SqStack &s,ElemType &x){ if(StackEmpty(s)) return false;//判断是否为空栈 x=s.data[s.top];/先出栈 s.top-=1;//再减一 /*书中s.top--同理*/ return true; }获取栈顶元素 bool GetTop(SqStack s,ElemType &x){ if(StackEmpty(s)) return false;//空 x=s.data[s.top]; return true; }入栈/出栈操作要注意s.top指针是从-1开始还是从0开始。共享栈 共享栈是指两个栈共享一块数组空间,那么根据栈的特性,很容易想到这块空间应当是栈底在这个数组空间两端,栈顶相向而行。 设置数组有MaxSize个元素,也就是说这个数组的有效下标从0到MaxSize-1,意味着呢,top0\=\=-1时代表着0号栈为空,top1\=\=MaxSize代表1号栈为空,如果top1-top0 \=\= 1的时候代表栈满,0号栈的操作和上面的类似,1号栈与其正好反过来 共享栈优点就是两个栈空间可以相互调节。 栈的链式存储结构 代码描述如下: typedef struct LinkNode{ ElemType data; struct LinkNode *next; }LiStack;简直就是跟单链表一个样,没错就是一个样子的。 我们可以设置一个head结点指向链表头结点,以后无论什么操作,都限定只能对表头进行操作,这样也体现了栈的后进先出的特性。 队列 队列(Queue)是只允许在一端进行插入,在另一端删除的线性表 队列的定义 队列(Queue)是只允许在一端进行插入,在另一端删除的线性表。它也是一种线性表,但是它限制了其插入和删除操作,相关概念: 队头 :允许删除的一端,又叫队首 队尾: 允许插入的一端 空队列:不含任何元素的空表 对于队列这个数据结构,可以概括为它是一种进行先进先出操作的线性表(First In First Out,FIFO)。 队列的基本操作 队列的基本操作可以说和线性表的操作大差不差,同时结合队列自身的操作特性得到其基本操作:初始化一个队列、判断队列是否为空、入队、出队、获取队头元素、销毁队列,函数名就不多说了,写了这么多一定能写出来的。 队列的顺序存储结构 他利用地址连续的存储单元存放自队头到队尾的数据元素,同时也会设置一个队头(front)指针来指示队头元素位置,一个队尾(rear)指针来指示当前队尾元素(也有的教材指向队尾的下一个位置)位置。 #define MaxSize 50 //队列中最大的个数 typedef struct{ ElemType data[MaxSize];//队列中元素 int front;//队头指针 int rear;//队尾指针 }SqQueue;这里: 队头指针:S.front 初始时设置为0,队头元素S.data[s.front]; 队尾指针:S.rear 初始时设置为0,队尾 元素S.data[s.rear]; 入队:判断是否已满,先把值送到队尾元素,再+1。 出队:非空时,先取元素,再+1,同时返回该元素。 判空操作:S.front\=\=S.rear; 判满操作:S.rear\=\=MaxSize; 队列长度:S.rear-S.front; 当然如果队尾指针初始值是-1的时候就要另行再论了,他可能需要先+1再赋值。这个需要自行判断。顺序队列的一些基本操作 初始化: void InitQueue(SqQueue &q){ q.front=0; q.rear=0; }判空: bool QueueEmpty(SqQueue q){ if(q.front==q.rear) return true;//空 else return false;//不空 }入队: bool EnQueue(SqQueue &q,ElemType x){ if(q.rear==MaxSize) return false;//满 q.data[q.rear]=x;//先赋值 q.rear+=1;//再指针+1 return true; }出队: bool DeQueue(SqQueue &q,ElemType &x){ if(QueueEmpty(q)) return false;//判断是否为空队列 x=q.data[q.front];//先出队 q.front+=1;//再+1 return true; }获取队头元素: bool GetHead(SqQueue q,ElemType &x){ if(QueueEmpty(q)) return false;//空 x=q.data[q.front]; return true; }针对判断是否满的操作,有这样一个疑问,q.rear==MaxSize代表着队列满吗?答案是不一定。如下面的图示。md1e9aqd.png图片 本图d中虽然只有一个元素,但是q.rear\=\=MaxSize,这时入队出现了上溢,但这种溢出不是真正的溢出,我们仍可以存放元素,所以为了解决这个问题,引入了[[栈和队列#循环队列|循环队列]]的概念。循环队列 为了解决提到的假溢出问题,提高存储空间的利用率,我们把顺序队列臆想成为一个环形结构。当队首指针Q.front==Maxsize-1后再前进一个位置到达0,这种操作可以用模运算,也就是Q.front=(Q.front+1)%Maxsize来表示。 循环队列的一些基本操作: 判空与之前一样,还是Q.front==Q.rear。 入队: bool EnQueue(SqQueue &q,ElemType x){ if((q.rear+1)%MaxSize==q.front) return false;//满 q.data[q.rear]=x;//先赋值 q.rear=(q.rear+1)%MaxSize;//再指针+1 return true; }出队: bool DeQueue(SqQueue &q,ElemType &x){ if(QueueEmpty(q)) return false;//判断是否为空队列 x=q.data[q.front];//先出队 q.front=(q.front+1)%MaxSize;//再+1 return true; }补充:区分队空还是队满的三种处理方式: 牺牲一个单元来区分队空或者队满。入队时少用一个单元,约定以队首指针在队尾指针的下一个位置时尾队满,也就是(Q.rear+1)%MaxSize==Q.front代表队满,Q.front==Q.rear代表队空。 增加size数据成员变量,入队时size++,出队时size--,size==0时队空,size==MaxSize时队满。两种情况都满足Q.front==Q.rear。 增设一个标志位,如果删除成功就置0,插入成功就置1。如果Q.front==Q.rear且标志位为0代表队空,标志位为1代表队满。队列的链式存储结构 队列的链式表示又称为链式队列。他是一个同时具有队首指针和队尾指针的单链表,队首指针指向队头结点,队尾指针指向队尾结点。接下来我只写代码,就不多赘述了。 定义: typedef struct LinkNode{ ElemType data; struct LinkNode *next; }LinkNode;//链表结点 typedef struct{ LinkNode *front,*rear; }LinkQueue;//链式队列创建队列: void InitQueue(LinkQueue &q){ q.front=q.rear=(LinkNode *)malloc(sizeof(LinkNode));//建立一个头结点 q.front->next=NULL; }判空 bool QueueEmpty(LinkQueue q){ if(q.front==q.rear) return true;//空 else return false;//不空 }入队: bool EnQueue(LinkQueue &q,ElemType x){ LinkNode *s=(LinkNode *)malloc(sizeof(LinkNode));//新建一个结点 s->data=x;//赋值 s->next=NULL;//新结点的next指向NULL q.rear->next=s;//将新结点接到队尾 q.rear=s;//更新队尾指针 return true; }出队: bool DeQueue(LinkQueue &q,ElemType &x){ if(QueueEmpty(q)) return false;//判断是否为空队列 LinkNode *p=q.front->next;//指向队头结点 x=p->data;//先出队 q.front->next=p->next;//将队头结点的next指向下一个结点 if(q.rear==p) q.rear=q.front;//如果出队的是队尾结点,更新队尾指针 free(p);//释放队头结点 return true; }双端队列 双端队列:只允许从两端插入、两端删除的线性表 双端队列的定义 双端队列:只允许从两端插入、两端删除的线性表 针对双端队列的不同应用场景,又分为以下: 输入受限的双端队列:只允许从一端插入、两端删除的线性表 输出受限的双端队列:只允许从两端插入、一端删除的线性表 栈和队列的应用及考点 罗列几个以后可能会考到的考点,慢慢补 栈的括号匹配 栈的表达式求值 栈在递归中的应用 队列在层次遍历中的作用 队列在操作系统的应用 双端队列的输出序列问题
-
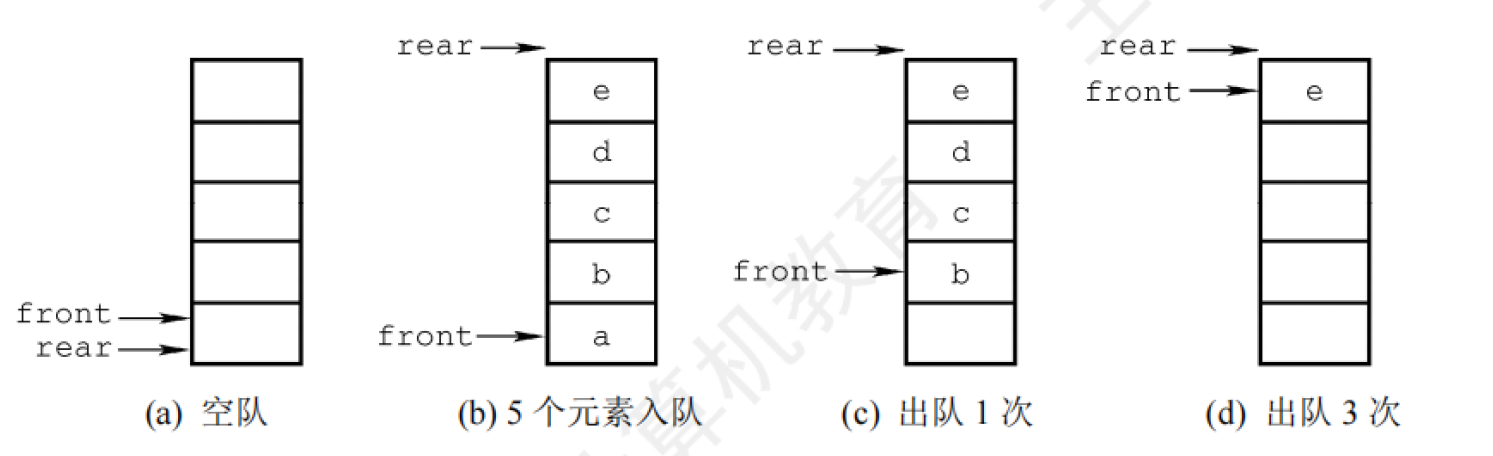
【计算机考研(408)- 数据结构】绪论 绪论 基本概念(理解即可) 数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别 和处理的符号的集合。数据是计算机程序加工的原料。(For Example : 声音/图像/字符串等) 数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。 一个数据元素可由若干数据项组成,数据项是构成数据元素的不可分割的最小单位。(For Example : 书籍信息是一个数据元素,其中的书名/价格/作者/ISBN等信息作为一个又一个的数据项) 数据结构是相互之间存在一种或多种特定关系的数据元素的集合。 数据对象是具有相同性质的数据元素的集合,是数据的一个子集。 数据结构三要素 不难知道,数据元素之间都不是孤立存在的,一定存在某种关系,这种数据元素之间的关系我们称之为结构。根据相关特性一般可以分为以下四种: 集合 线性结构 树形结构 图状结构或网状结构 他们说明的是数据元素之间的逻辑关系,也叫做:逻辑结构。 那么 数据结构在计算机中的表示(也称映像),也就被称作物理结构。它包括数据元素的表示和关系的表示。一般地,我们有以下几种主要的物理结构: 顺序存储(以物理位置相邻表示逻辑上的相邻) 链式存储(形成链状) 索引存储(建立索引表) 散列存储(根据关键字算存储位置) 施加在数据上的运算包括运算的定义(逻辑)和实现(物理)被称之为数据的运算。 数据类型、抽象数据类型 数据类型是一个值的集合和定义在此集合上的一组操作的总称。 原子类型:其值不可再分的数据类型。(如bool & int) 结构类型:其值可以再分解为若干成分(分量)的数据类型。(如class等) 抽象数据类型(Abstract Data Type,ADT):抽象数据组织及与之相关的操作。 ADT用数学化的语言定义数据的逻辑结构、定义运算。与具体的实现无关。算法和算法分析 算法 算法(Algorithm)是对特定问题求解步骤的一种描述,它是指令的有限序列,其中的每条指令表示一个或多个操作。从定义上和实际,他应具备如下五种特性: 有穷性。一个算法必须总在执行有穷步之后结束,且每一步都可在有穷时间内完成。 确定性。算法中每条指令必须有确切的含义,对于相同的输入只能得出相同的输出。 可行性。算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。 输入。一个算法有零个或多个输入,这些输入取自于某个特定的对象的集合。 输出。一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。 对于一个”好“算法一定要达到以下目标: 正确性。算法应能够正确地解决求解问题。 可读性。算法应具有良好的可读性,以帮助人们理解 健壮性。输入非法数据时,算法能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果。 高效率(时间复杂度低)与低存储量需求(空间复杂度低) 算法效率的度量 时间复杂度 一个语句的频度是指改语句在算法中被重复执行的次数。算法中所有语句的频度之和被记为$T(n)$。他是关于该算法问题规模n的函数,时间复杂度主要分析$T(n)$的数量级。算法中基本运算(最深层的语句)的频度与$T(n)$同数量级每一次通常将算法中基本运算的执行次数的数量级作为该算法的时间复杂度。于是时间复杂度可以定义为: $$T(n) = O(f(n))$$ 当然,最终我们写出的时间复杂度应取随n增长最快的项,将其系数置为1作为时间复杂度的度量,例如$f(n) = 3n^2 + 2n + 1$,则$T(n) = O(n^2)$。在分析时间复杂度的时候,有以下两条规则: 加法规则:$T(n) = T_1(n) + T_2(n) = O(f(n)) + O(g(n)) = O(\max(f(n), g(n)))$ 乘法规则:$T(n) = T_1(n) \times T_2(n) = O(f(n)) \times O(g(n)) = O(f(n) \times g(n))$ 常见的渐进时间复杂度有: $$ O(1) < O(\log_2 n) < O(n) < O(n \log_2 n) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n) $$图像表示: 渐进时间复杂度得图像表示(例)图片 相应的我们还有如下定义: 最坏时间复杂度:最坏情况下算法的时间复杂度 平均时间复杂度:所有输入示例等概率出现的情况下,算法的期望运行时间 最好时间复杂度:最好情况下算法的时间复杂度 空间复杂度 算法的空间复杂度$S(n)$定义为该算法所需的存储空间,他是一个关于算法问题规模n的函数。记为: $$S(n) = O(f(n))$$ 他的计算方法与时间复杂度类似,主要分析算法中基本存储单元的使用情况。空间复杂度的计算也有加法和乘法规则。(不在赘述在此) 一个程序在执行时除了需要存储空间来存放自身所用的指令、常数、变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为实现计算所需信息的辅助空间。若输入数据所占空间只取决于问题本身,和算法无关,则只需要分析除输入和程序之外的额外空间。如果算法原地工作是指算法所需的辅助空间为常量,即$S(n) = O(1)$。 也就是说:空间复杂度为$O(1)$代表算法所需辅助空间的大小与问题规模无关。 举例: void test(int n){ int a[n]; int i; }上面代码中,数组a的大小与n有关,因此空间复杂度为$O(n)$。 void test(int n){ int i; }上面代码中,变量i的大小与n无关,因此空间复杂度为$O(1)$。 void test(int n){ int a[n][n]; }上面代码中,数组a的大小与n有关,因此空间复杂度为$O(n^2)$。 void test(int n){ int a[n]; int b[n][n]; int i; }上面代码中,数组a的大小与n有关,数组b的大小与n有关,因此空间复杂度为$S(n) = O(n^2)+O(n)+O(1)$,根据加法原则:$S(n)=O(n^2)$
-
青春为中国式现代化挺膺担当 中国共产党党徽图片 站在 2025 年 6 月 12 日这个镌刻着特殊意义的日子里,我的内心始终被一股滚烫的力量激荡着 —— 从这一天起,我正式成为了一名中共预备党员。回首过往近三年的逐梦之路,从 2022 到 2023 再到 2025。 初次提笔写下入党申请书时,我满怀着对党的崇敬与向往。通过学习,我深刻认识到中国共产党自成立以来,始终是中国特色社会主义事业的领导核心,团结带领人民创造了一个又一个伟大奇迹。新时代新征程上,推进中国式现代化的宏伟蓝图徐徐展开,这是实现中华民族伟大复兴的康庄大道,也让我更加坚定了加入这个光荣集体的决心,渴望将个人奋斗融入时代浪潮,为国家发展贡献力量。 成为入党积极分子后,我以更高的标准要求自己。在学习中,我不断钻研专业知识,积极参与学术研讨,力求用扎实的学识武装自己,为投身中国式现代化建设储备能量;在生活里,我主动参与社区志愿服务,让我体会到为人民服务的快乐与价值,也更加深刻理解了党的宗旨。 当被确定为发展对象,我愈发感受到肩头责任的沉重。在党组织的培养和教育下,我深入学习党的二十大精神,深刻领会中国式现代化的中国特色和本质要求。我认识到,中国式现代化是人口规模巨大的现代化、是全体人民共同富裕的现代化、是物质文明和精神文明相协调的现代化、是人与自然和谐共生的现代化、是走和平发展道路的现代化。这一伟大事业需要一代又一代有志青年接力奋斗。 如今,光荣加入党组织,不仅是一份荣誉,更是一份沉甸甸的责任。作为新时代的青年党员,我将牢记习近平总书记对青年 “自找苦吃” 的殷殷嘱托,以青春之名,挺膺担当。在今后的日子里,我会持续加强理论学习,用党的创新理论武装头脑,坚定不移听党话、跟党走;立足本职岗位,将个人理想融入国家发展大局,在科技创新、乡村振兴、基层治理等领域发光发热;始终保持与人民群众的血肉联系,用心用情解决群众急难愁盼问题,践行全心全意为人民服务的根本宗旨,让青春在全面建设社会主义现代化国家的火热实践中绽放绚丽之花。 mc2wj7ck.png图片
-
【计算机考研(408)- 数据结构】线性表 线性表 什么是线性表 线性表一般是由相同的数据类型的若干(n)个数据元素构成的有限序列,如果里面没有元素,则称之为空表。如果用L命名线性表,一般表示为: $$ L=(a_1,a_2,…,a_i ,a_{i+1},…,a_n) $$其中用n为表长,当n=0时线性表为一空表。 在式子中,$a_1$是唯一的第一个数据元素,也被称作表头元素。同理$a_n$ 是唯一的最后一个数据元素,也就被称为表尾元素。除第一个元素外,每个元素都有且仅有一个直接前驱,除最后一个元素外,每个元素又有且仅有一个直接后继。故而线性表具有线性有序的逻辑结构。 据此我们很容易就得到了线性表的特点: 个数有限 逻辑有序 每个元素都素单个的数据元素 数据类型相同(意味着他们每一个元素都应占用相同大小的存储空间) 抽象(无论他们什么内容,线性表都是一种元素之间的逻辑关系) 线性表的每个数据的类型都是相同的,每个元素都应有其前后的对应关系,当然,第一个数据没有前面的元素,最后一个没有后面的数据。 线性表的操作也很简单,创建/初始化一个线性表、销毁一个线性表、将线性表置空、判断线性表是否是空的、线性表元素的个数、返回表中第几个元素的值(按位查找)、返回第一个与传入值相同的值(按值查找)、返回他的下一个值(后继)(除最后一个)、返回他的(前驱)前一个(除第一个)、插入一个值、删除一个值、遍历这个表 很多不同的书籍对于其操作都是是有不同理解的,但是基础操作例如:初始化,删除,置空,插入值,返回值,遍历,查找等,都是不可缺少的,通过组合基本的操作来实现自定义的操作。 线性表的顺序存储结构 顺序表的定义和地址 线性表的顺序存储结构又叫做顺序表,他用一组地址连续的存储单元依次存储线性表中的数据元素,从而使逻辑上相邻的两个元素,再计算机中的物理位置也相邻。第一个元素存储在顺序表的起始位置。第i个元素的存储位置的下一个也一定是第i+1个元素,那么这个i为元素$a_{i}$在顺序表中的位序。因此,顺序表的特点就是表中元素的逻辑顺序与其存储的物理顺序相同。 对于线性表他的物理地址一般是相邻的,可以很容易地计算其存储位置: 如果每个元素需要n个存储单元,以第一个数据所在位置的存储地址为存储起始位置,则第i+1个元素的地址和第i个元素的存储位置满足下列关系:1 $$ LOC(a_{i+1})=LOC(a_i)+sizeof(ElemType) $$类比推算(等差数列也可)得出: $$ LOC(a_i)=LOC(a_1)+(i-1)*sizeof(ElemType) $$通过这个公式可以得知,可以随意算出任一位置的地址,他们都是相同的时间,每个数据元素的存储位置和顺序表的表头元素相差一个和位序成正比的常数,所以在存入和取出数据的时候所消耗的时间都是常数的,复杂度即为O(1),通常把这种特性的结构称之为随机存取结构,故而线性表的顺序存储结构是一种随机存取的存储结构。 通常利用数组描述线性表的顺序存储结构,但是,线性表中元素的位序从1开始,然而数组的元素下表却是从0开始的。存储结构描述 #define MAXSIZE 20 //先行不熬自打长度 typedef struct { ElemType data[MAXSIZE];//此处的ElemType 可以换成任意一种数据类型(例如:int/float/char)//表中的元素 int length;//长度 }List;//(线性表)由此我们能看到,数组data是存储数据的存储位置,他有一个最大的存储容量MAX=20,一个数据用来记录这个表的长度。 这里有个地方就是MAXSIZE是指的是这个数组所占空间长度为20,是预先分配的存储空间长度,而length指的是有数据的长度,也就是表的长度。 当然一维数组可以是静态分配的,也可以是动态分配的。对数组进行静态分配的时候,数组的大小/空间已经事先定义好了,一旦空间满了再加入新的数据就会溢出。 刚才的代码是一种静态存储的方式,在动态分配的时候,存储数组的空间实在程序执行的时候通过动态存储分配语句分配的,一旦满了,就在开一块更大的空间,原先的数据全部拷贝到新空间中,从而达到扩充数组存储空间的目的,而非为线性表一次性划分所有空间。参考如下代码描述: #define InitSize 100 //表初始空间100 typedef struct{ ElemType *data;//动态分配数组的指针 int MaxSize;//最大容量 int length;//表长度 }List在C语言中可以用malloc来获取空间,故而初始定义语句如下: List L;//定义一个新的顺序表 L.data=(ElemType* )malloc(sizeof(ELemType) * InitSize);在C++的语句就如下所示: List L; L.data= new ElemType[InitSize];很显然C++更容易懂一些。 书中说,动态分配并不同于链式存储,他依旧具备随机存储的特性。顺序表的特点很明显: 随机访问,首地址+位序就可以在常数时间内找到 存储密度很高,不像链式存储需要存储指针域 缺点也很明显: 插入/删除操作需要移动元素。复杂度分析见后 需要一块连续的存储空间(不灵活) 顺序表中各种基础操作的实现 笔记约定:全文对于C++写起来更好的代码,我会尽量使用C++语法,比如如下的bool: #define OK 1 #define ERROR 0 typedef int Status; //之后把所有bool的地方改成Status,return的值分别为OK 和 ERROR开始前的准备 //头文件 #include<iostream> //我们把自定义数据类型(ElemType)设置为int #define ElemType int //顺序表的定义 #define MAXSIZE 20 typedef struct { int data[MAXSIZE];//此处的int 可以换成任意一种数据类型 int length; }List;//(线性表)初始化操作 以动态分配为例 void InitList(List &L){ L.data = new ElemType[IniSize];//动态分配存储空间 L.length=0;//静态分配只需要这个就可以,设置当前表长为0 L.MaxSize=InitSize//初始容量 }插入操作 //插入操作 bool ListInsert(List *L,int i,ElemType e)//e还是这个线性表的数据类型 { if(L->length>=MAXSIZE) return false;//表示表满了,应该返回一个false if(i<1||i>L->length+1) return false;//此举判断i是否符合插入要求 for(int k=L->length;k>=i;k--) { L->data[k]=L->data[k-1];//依次后移 } L->data[i-1]=e; L->length++; return true; }Warning: 顺序表位序从1 开始,而数组下标从0开始,故而k=L->length就代表着表示这个表的数组最后一个元素的下一个值复杂度分析: 假设$p_{i}$是在第i个元素之前插入一个元素的概率,$E_{insert}$为长度为n的线性表插入一个元素所需移动元素次数的期望值(平均次数),则有: $$ E_{insert}=\sum^{n+1}_{i=1}p_i(n-i+1) $$每个位置插入是等概率的p=1/(n+1) 则: $$ E_{insert}=\frac{1}{n+1}\sum^{n+1}_{i=1}(n-i+1)=\frac{n}{2} $$所以,插入算法的平均复杂度为$O(n)$。 也很好理解,最好情况就是移动0次,最坏情况就是移动n次,故而平均次数为n/2。 删除操作 我看书中还要还要返回这个值,可以通过传入一个引用参数传回,不写了。 //删除操作 bool ListDelete(List *L,int i) { //在顺序表L中删除第i个元素,i值的合法范围是1≤i≤L.length if((i<1)||(i>L.length)) return false; //i值不合法 for(j=i;j<=L.length;j++) L.data[j-1]=L.data[j]; //被删除元素之后的元素前移 L.length--; return OK; }还要注意刚才的位序和数组下标之间的关系复杂度分析: 删除和插入都是相似的都在于其时间都在移动元素之上,同理假设所有位置删除的概率为相同,p=1/n,则: $$ E_{delete}=\frac{1}{n}\sum^n_{i=1}(n-i)=\frac{n-1}{2} $$因此啊,时间复杂度还是$O(n)$。 再一个就是,删除尾部移动0次,删除头部移动n-1次,平均还是(n-1)/2。 获取某个位置元素(按位查找) 按位查找有点脱裤子放屁,其实可以直接根据下标返回值的,这是随机存储特性啊! bool GetElem(List L,int i,ElemType& e)//此处的e代表我要返回的值,数据类型需要自己去改变 { if(L.length==0||i<1||i>L.length) return false; *e=L.data[i-1];//这里减一的原因我i传入的应该从1开始计数,而不是像数组一样从0开始计数 return true; }//代码用到了Bool类型判断这个函数是否能正常运行按值查找 //查找 int Locate(List L,ElemType e) { for(int i=0;i<L.length;i++) { if(L.data[i]==e) return i+1; } return 0;//没找到 }复杂度分析: 查找用ASL(平均查找长度)来进行讨论,假设pi 是查找第i个元素的概率,Ci 为找到表中其关键字与给定值相等的第i个记录时,和给定值已进行过比较的关键字个数,则在长度为n的线性表中,查找成功时的平均查找长度为: $$ ASL=\sum_{i=1}^0p_iC_i $$假设每个元素被找到的概率为相同的: $$ p_i=\frac{1}{n} $$那么可以简化成: $$ ASL=\frac{1}{n}\sum_{i=1}^0i=\frac{n+1}{2} $$故顺序表按值查找算法的平均时间复杂度为O(n)。 还可以这么理解:正好在表头找1次,表尾找n次,平均(n+1)/2。 线性表的链式存储结构 顺序表存储位置很直观/很简单就可以被计算,它可以随机存取表中任意一个元素,但是删除和插入需要移动大量元素,然而链,顾名思义,它使用链来建立元素之间的关系,所以删除和插入都仅需要修改指针,当然也就失去了顺序表随机存取的特性 单链表的定义及其代码描述 线性表的链式存储结构特点是:用一组任意的存储单元来存储线性表的元素(区别于线性表,这组空间可连续,也可不连续),所以,要表示这个元素和他后一个元素之间的相互关系,除了存储他本身的数据外,我们还需要存储一个指示他的后继的信息。这两者共同组成的内容我们称之其为节点,它包括两个域,他存储数据元素信息的域称之为数据域,存储他的后继位置的域称之为指针域。若干个节点链接成为一个链表,则可称之其为线性表的链式存储结构,又因为只包含一个指针域,又称之其为线性链表或单链表。 也就是说啊,这个链式存储结构包含一个数据和一个指向下一个元素的指针,所以,用C/C++的想法来写如下所示: typedef struct LNode{ Elemtype data;//数据域,自定义数据类型 struct LNode *next;//指针域,同时为了保证C语言同样能运行,要声明LNode是一个结构体 }LNode, *LinkList;单链表可以解决顺序表需要大量连续的存储单元的缺点,但是其比顺序表多出来的指针域,其实也在浪费空间,这是他的一个缺点。单链表各个元素离散地分布在存储空间中,因此它具有非随机存储的存储结构,那也就也意味着,如果要查找特定结点的话,需要从头开始遍历,依次查找 同时,为了方便,单链表一般会引入一个头节点(文学造纸很高:节点/结点傻傻分不清楚),其data不赋值,他的next指向首元结点(就是第一个有数据的结点)。他主要目的就是标识一个链表,指出其起始地址,这个结点也就是头结点。在记录的时候,头节点可以存储一些例如表长的一些信息,当指针域为空(NULL)的时候(尾结点),可以使用“^”表示。 头结点和头指针:无论是否有头结点,头指针一定指向链表的第一个节点,头结点是带头结点的链表的第一个结点,通常数据域为NULL。引入这个所谓的头结点能给我们带来如下好处: 第一个结点的一些操作和其他节点的操作一致,参考基本操作实现 无论链表是否为空,头指针一定指向了头结点的非空指针(空表的头结点的指针域就为空),因此空与非空表的处理也就得到了统一 单链表的基本操作实现 准备工作(头文件等) #include<iostream> using namespace std; typedef int Elemtype;//设置自定义类型为int //引入定义 typedef struct LNode{ Elemtype data;//数据域,自定义数据类型 struct LNode *next;//指针域,同时为了保证C语言同样能运行,要声明LNode是一个结构体 }LNode, *LinkList;初始化(Init) bool InitLinkList(LinkList &L)//传入一个地址 { L=new LNode;//创建一个新的结点 L->next=NULL;//或L->next=nullptr; return true; /* //不带头结点的初始化 L=NULL: retrun true; */ }求表长 //计算结点个数 int Length (LinkList L) { int len = 0; LNode *p = L; while(p->next!=NULL) { p=p->next; len++; } retunr len; }时间复杂度O(n),注意此代码为带头结点求个数,如果不带头结点那么就是判断while(p!=NULL)了;获取某个位置的值(按位查找) bool GetElem(LinkList L,int i,Elemtype &e) { LNode *p=L->next; int j=1;//头结点是第0,那么第一个结点就是第一个。 while(p&&j<i)//这一步想要让这个p到达i位置,直接判(p)就是指p不为NULL { p=p->next; j++; } if(!p||j>i) return false;//i值不可以大于0,或者当p一定到头了,但是还是没有取到i,也要返回false,!p就是p为NULL e=p->data;//取i结点的数据 return true; }注意本代码中是带头节点的链表此代码复杂度分析: 还是按照我们的,还是假设每一个被取值的概率相等,每次取值都需要执行i-1次p=p->next,根据之前的公式: $$ ASL=\frac{1}{n}\sum^n_{i=1}(i-1)=\frac{n-1}{2} $$由此单链表的取值算法复杂度为O(n)。 按值查找 LNode *LOCATE(LinkList L,Elemtype e)//查找第一个值等于e的函数 { LNode* p=L->next; while(p&&p->data!=e) p=p->next; return p;//如果没找到我们就返回NULL,这串代码执行到最后没找,会到达p=NULL; }算法复杂度同上,仍为O(n)。 插入结点 bool ListInsert(LinkList &L,int i,Elemtype e) { LNode *p=L; int j=0; while(p->next&&(j<i-1)) { p=p->next; j++; } if(!p||j>i-1) return false;//这种情况就是i<1和i的值超过了链长 LNode *s=new LNode; s->data=e; s->next=p->next; //操作1 p->next=s; //操作2 return true; }注意代码操作顺序,操作1和2不可颠倒位置互换。此代码复杂度类似于获取某个位置的值(按位查找)的算法,因为都要找到i这个位置,复杂度为O(n)。 删除结点 bool ListDelete(LinkList &L,int i) { LinkList p = L; int j = 0; while ((p->next) && (j < i - 1)) { p = p->next; j++; } if (!(p->next) || (j > i - 1))//删除位置不合理就要返回一个不正确的值 { return false; } LinkNode *s = p->next;//保存需要被删除的节点,方便后面的释放 p->next = s->next; free(s); return true; }类似插入算法,复杂度为O(n)。 头插/尾插法建立单链表 创建单链表,这个思路就是,当我们输入一个数据,新建一个节点,数据域就是我们输入的数据,指针域指向后继,当然,创建单链表还分为前插法和后插法,前插法顾名思义,当我创建了一个新的结点想要插入链表的时候,(头节点)L->next=新的结点,他的指针域指向上一个结点,后插法相反,代码示例: void CREATE_H(LinkList &L,int n)//前插n个元素 { L=new LNode; L->next=NULL; for(int i=0;i<n;i++) { p=new LNode; std::cin>>p->data;//输入数据域 p->next=L->next; L-next=p;//更改头节点指向 } }复杂度分析:每个结点插入的时间为O(1),但是需要插入n个元素,总的时间也是O(n)。这种情况插入的顺序可能和输入顺序不符,可以用来实现链表逆置。 对于没有头结点的头插法,还啊哟注意,每次插入新节点后,都需要将他的地址赋值给Lvoid CREATE_T(LinkList &L,int n)//后插法 { L=new LNode; L->next=NULL; LNode *r=L; for(int i=0;i<n;i++) { p=new LNode; std::cin>>p->data;//输入数据域 p->next=NULL; r->next=p; r=p;//更改头节点指向 } }复杂度分析:如果L是尾指针,那么就是和上面同样的分析思路。 双向链表 双向链表他有个直接前驱和后继,这样他的指针域就包含了两个指针,一个前驱,一个后继,其他和正常链表无差别。但是要注意的是,他的头节点的指针域指向的是第一个元素,而不是第一个元素的前驱。删除的时候,需要修改4个指针。 代码描述如下所示: typedef struct DNode{ ElemType data;//数据域 struct DNode *prior,* next;//前驱/后继 }在双向链表中,有些操作(如ListLength、GetElem和LocateElem等)仅需涉及一个方向的 指针,则它们的算法描述和线性链表相同,但在插入、删除时有很大的不同,在双向链表中进 行插入、删除时需同时修改两个方向上的指针,在插入节点时需要修改4个指针,在删除节点时需要修改两个指针。两者的时间复杂度均为O(n)。 插入操作: //将s结点插入到p之后 s->next=p->next;//s插入p的后面 p->next->prior=s;//p的下一个结点的前驱指向待插入结点s s->prior=p;//s前指于p p->next=s;//p指向s顺序不唯一,但不任意,比如p->next指向s这步,一定要在s->next=p->next。删除操作: //删除q p->next=q->next; q->next->prior=p; free(q);循环链表 循环链表是另外一种链式的存储结构,他的最后一个结点指向头节点,这样构成了一个环,差别在于,以前我们需要判结束,直接P->next==NULL就是结尾了,现在变成了p->next==L才是结束。 循环单双链表的基本操作和各自的操作是相同的,而且还不需要判定是否在表尾。 循环链表还可以设置头尾指针,这样无论尾插还是头插法都只需要O(1)复杂度。 静态链表 静态链表是用数组描述的线性表的链式存储结构,结点也有数据域和指针域,这里的指针域指的是在数组的相对地址,也称作游标。描述如下: #define MAXSIZE 50//最大值 typedef struct{ ElemType data;//数据域 int next;//指针域 }SLinkList[MAXSIZE];next == -1时为结束标志。顺序表和链表之间的性能分析 全文参考:[1]严蔚敏,李冬梅,吴伟民.数据结构(C语言版) [J].计算机教育, 2012(12):1.DOI:CNKI:SUN:JYJS.0.2012-12-017. (1)存储空间的分配顺序表的存储空间必须预先分配,元素个数有一定限制,易造成存储空间浪费或空间溢出现象;而链表不需要为其预先分配空间,只要内存空间允许,链表中的元素个数就没有限制。 基于此,当线性表的长度变化较大,难以预估存储规模时,宜采用链表作为存储结构。 (2)存储密度的大小 链表的每个节点除了设置数据域用来存储数据元素外,还要额外设置指针域,用来存储指 示元素之间逻辑关系的指针,从存储密度上来讲,这是不经济的。所谓存储密度是指数据元素本身所占用的存储量和整个节点结构所占用的存储量之比,即: $$ 存储密度=\frac{数据元素本身占有的存储量}{节点结构占用的数据量} $$存储密度越大,存储空间的利用率就越高。显然,顺序表的存储密度为1,而链表的存储密度小于1。如果每个元素数据域占据的空间较小,则指针的结构性开销就占用了整个节点的大部 分空间,这样存储密度较小。例如,若单链表的节点数据均为整数,指针所占用的空间和整型 量所占用的相同,则单链表的存储密度为0.5。因此,如果不考虑顺序表中的空闲区,则顺序表 的存储空间利用率为100%,而单链表的存储空间利用率仅为50%。基于此,当线性表的长度变化不大,易于事先确定其大小时,为了节约存储空间,宜采用顺序表作为存储结构。 时间性能的比较 (1)存取元素的效率,顺序表是由数组实现的,它是一种随机存取结构,指定任意一个位置序号i,都可以在O(1)时间内直接存取该位置上的元素,即取值操作的效率高;而链表是一种顺序存取结构,按位置访问链表中第i个元素时,只能从表头开始依次向后遍历链表,直到找到第i个位置上的元素,时间复杂度为O(n),即取值操作的效率低。基于此,若线性表的主要操作是和元素位置紧密相关的一类取值操作,很少做插入或删除时,宜采用顺序表作为存储结构。 (2)插入和删除操作的效率,对于链表,在确定插入或删除的位置后,插入或删除操作无须移动数据,只需要修改指针,时间复杂度为O(1)。而对于顺序表,进行插入或删除时,平均要移动表中近一半的节点, 时间复杂度为O(n)。尤其是当每个节点的信息量较大时,移动节点的时间开销就相当可观。基于此,对于频繁进行插入或删除操作的线性表,宜采用链表作为存储结构。 LOC函数指返回此数据的存储位置的函数,sizeof(ElemType)函数可以计算出ElemType在内存中所占字节数(C语言)。 ↩
-
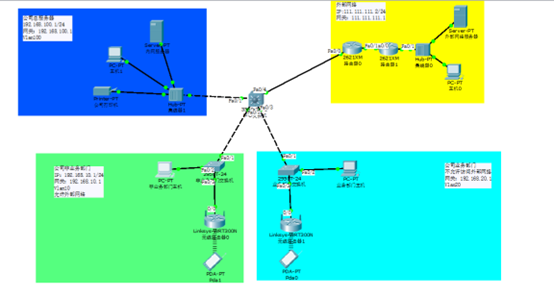
课程设计报告-组建小型企业局域网 课程设计报告-组建小型企业局域网 摘要 本课程设计聚焦于小型企业局域网的建设,旨在通过融合VLAN(虚拟局域网)技术和NAT(网络地址转换)技术,展示一个高效、安全的小型企业网络组建过程。课程设计首先分析了小型企业网络的建设需求接着,结合子网划分,详细阐述了如何为每个部门配置不同的VLAN,并规划相应的IP地址范围。在外部连接方面,NAT技术被引入,以允许内部设备使用私有IP地址访问外部网络,同时保护内部网络结构不被外部攻击。课程设计还包含了网络拓扑结构设计、交换机与路由器的配置、安全与管理措施以及故障排除方法等内容。通过这一综合性的课程设计,掌握NAT技术配置、三层交换机配置、子网划分等相关计算机网络技术等。课程设计中使用模拟软件Cisco Packet Tracer对设备进行配置,包括IP地址的规划、路由协议的选择以及交换机的配置等。 关键词:虚拟局域网,网络地址转换,三层交换机,子网划分 [toc] 一、课程设计的目的及要求 1.1 课程设计目的 通过一周的课程设计,培养进一步理解和掌握网络组网的过程及方案设计,为今后从事实际工作打下基础;熟练掌握子网划分及路由协议的配置,熟练掌握路由器和交换机的基本配置。 1.2 课程设计要求 要求能根据实际问题绘制拓扑结构图,拓扑结构图可以是树形、星形、网状形、环状形及混合形结构的之一,清晰的描述接口,进行路由器或交换机的命令配置实现,并且每个方案的需有以下几部分的内容: 1.3 课程设计题目要求 现有200台计算机,设计一个小型企业网络方案,要求: 1.资源共享,网络内的各个桌面用户可共享数据库、共享打印机,实现办公自动化系统中的各项功能; 2.通信服务,最终用户通过广域网连接可以收发电子邮件、实现Web应用、接入互联网、进行安全的广域网访问; 3.划分网段; 4.选择路由协议,配置路由,并为路由器设置密码。 二、课程设计的内容(分析和设计) 2.1 需求分析 2.1.1 需求分析背景 当前,小型企业大多拥有两种类型的业务系统:一种是需要同时访问公网和内网的非业务部门(如市场部、销售部等),另一种则是不需要访问公网、仅需在内网中运行的业务部门(如财务部、人力资源部等)。同时也随着社会信息化的发展,无论是报销还是流程化办公,都需要一个内网来部署一套OA系统,这也就需要所有设备都能连接到公司的内部网络服务器,实现自动化、流程化。而且现在配置网络,也需要考虑到便携设备能够顺畅接入网络,也就需要无线路由器来设置无线局域网络。 2.2 网络结构划分 基于上述分析,我们将整个内部网络划分为以下四个主要部分: 公司总服务器:作为整个企业网络的核心,负责存储和管理企业的重要数据、应用程序及网络资源。总服务器应具备高可靠性和高性能,以确保企业业务的连续性和稳定性。 业务部门:这些部门主要处理企业内部事务,不需要访问外部网络。因此,在网络安全策略上,可以对这些部门的网络访问进行更严格的限制,以降低外部攻击的风险。 非业务部门:这些部门需要频繁访问外部网络(如公网),以进行市场推广、客户服务等活动。为了确保这些部门的网络访问效率和安全性,需要为其配置高速、稳定的网络连接,并加强网络安全防护措施。 外部网络:包括互联网、合作伙伴网络等外部资源。企业需要通过安全、可靠的方式与外部网络进行连接,以实现信息共享和业务协同。 2.3 综合设计 2.3.1 内部网络设备选择 考虑到小型企业的需求,需要尽可能少的投入,获得更好的网络效果,所以我在整个网络的核心选择了三层交换机,这样既可以做到各个子网之间的互通,又节约了资金,也方便了管理人员日后维护 深入到两个业务系统我就选择了交换机(其实这里也可以选择集线器的),这个主要是考虑到交换机他以后的扩展性,可以划分Vlan,因为可能真正的环境中可能需要一个部门既有能访问公网的设备,又有不能访问公网的设备 对于外部网络连接,我主要选择了路由器来做网络地址转化和访问控制 2.3.2 外部网络接入 目前的互联网服务提供商针对小型企业的接入方式有PPPOE、ADSL宽带接入、公网IP等。但是无论是什么接入到Internet都会有给一个能够访问外部的IP,所以我在本模拟选择了111.111.111.1/24作为外部网络。 2.3.3 线材选取 在构建小型企业网络时,线材的选择同样至关重要,它不仅关系到网络的稳定性和传输速度,还直接影响到网络的扩展性和维护成本。因此,在综合考量了网络设备的选择后,我精心挑选了以下线材来完善整个网络架构: 网线(以太网电缆): 类型:考虑到成本效益和传输性能,我选择了常用的Cat5e或Cat6网线。Cat5e网线支持千兆以太网传输,而Cat6网线则提供了更高的带宽和更出色的抗干扰能力,为未来可能的网络升级预留了空间。 长度:根据网络设备之间的实际距离,我选择了适当长度的网线,以确保信号传输的稳定性和效率。同时,也预留了一定的冗余长度,以便于日后的维护和调整。 光纤线: 应用场景:虽然光纤线成本较高,但在需要长距离传输或高带宽需求的场景中,它无疑是最佳选择。因此,如果小型企业网络中存在跨楼层或远距离的通信需求,我会考虑引入光纤线来构建主干网络。 类型:根据实际需求,我会选择单模或多模光纤线,并配备相应的光纤收发器或交换机来支持光纤通信。 2.3.4 布线设计 考虑到小企业或小公司的使用面积有限,我们将总服务器和核心交换机集中放置于同一位置,如网络机房或办公室的一角。这样的布局不仅节省了空间,还有利于网络的集中管理和维护。 为了实现多口接入,我们可以在核心交换机旁边配置分线器或小型交换机。这些设备能够将核心交换机的端口进行扩展,以满足更多设备的接入需求。同时,它们也便于日后的网络扩展和升级。 2.3.5 模拟组网 我们使用模拟软件Cisco Packet Tracer对设备进行配置,包括IP地址的规划、路由协议的选择以及交换机的配置等。对各个部门的IP地址分配和划分的Vlan如表2.1所示,所选取的模拟设备如表2.2所示。 部门预计使用IP地址Vlan公司服务器4192.168.100.1/24100外网服务器2111.111.111.1/24不适用业务部门100192.168.10.1/2410非业务部门100192.168.20.1/2420部门设备使用目的分配IP公司服务器Server PT公司内部服务器192.168.100.3公司服务器PC-PT模拟连接在服务端的计算机设备管理服务器。DHCP公司服务器HUB-PT集线器不适用公司服务器其他设备模拟公司的打印机等公共设备DHCP中心设备三层交换机3560-24PS三层交换机,提供Vlan、DHCP、Vlan间的相互通信不适用业务部门2950T-24交换机连接上下层设备不适用业务部门PC-PT模拟办公电脑DHCP业务部门其他设备模拟办公环境DHCP业务部门WRT300N无线网络DHCP非业务部门2950T-24交换机连接上下层设备不适用非业务部门PC-PT模拟办公电脑DHCP非业务部门其他设备模拟办公环境DHCP非业务部门WRT300N无线网络DHCP外部网络使用Server-PT、PC-PT模拟外部网络。两个路由器实现外部网络IP地址转化。 三、绘制拓扑结构图 1735557594490图片 四、详细步骤 4.1 配置各部门的交换机 遵照以下步骤执行:首先,用交叉线连接至三层交换机,用直通线连接各个用网设备,将直接连接三层交换机的端口设置为trunk,其他端口为access,并各自配置自己的Vlan。具体代码见5.1。 4.2 配置三层交换机 遵照以下步骤执行:首先连接好线缆(如图5-1所示)fa0/1连接到了公司服务器,fa0/2 fa0/3分别连接到了非业务部门、业务部门,fa0/4连接到了外部网络的路由器上。 将fa0/1设置为access vlan100,fa0/2-fa0/3设置为trunk,fa0/4为2层模式,代码详见5.3 接着为各个Vlan配置IP地址,代码详见5.4,并配置DHCP服务器,代码详见5.2 接着配置路由,将fa0/4的ip设置为10.0.0.1,并且将0.0.0.0/0 的下一跳地址改为10.0.0.2,代码详见5.5。 1735557615949图片 图5-1 中心交换机连接示意图 将fa0/1设置为access vlan100,fa0/2-fa0/3设置为trunk,fa0/4为2层模式,代码详见5.3。接着为各个Vlan配置IP地址,代码详见5.4,并配置DHCP服务器,代码详见5.2。接着配置路由,将fa0/4的ip设置为10.0.0.1,并且将0.0.0.0/0 的下一跳地址改为10.0.0.2,代码详见5.5。 4.3 配置外网地址转化路由器 首先配置第一个路由器:先将fa0/0端口的ip地址设置为10.0.0.2,子网掩码设置为255.255.255.2,fa0/1的ip地址设置为172.31.1.1,子网掩码设置为255.255.255.252。 接着配置路由,将192.168.0.0/16 的下一跳设置为10.0.0.1,将0.0.0.0/0的下一跳设置为172.31.1.2。 接着配置ACL,允许192.168.10.0/24通过,代码详见5.6。 接着配置网络地址转化,代码详见5.7。 最后将第二各路由器,将fa0/0端口的ip地址设置为172.31.1.2,子网掩码设置为255.255.255.2,fa0/1的ip地址设置为111.111.111.1,子网掩码设置为255.255.255.252。 4.4 配置无线路由器 首先在路由器的Internet配置中选择DHCP,因为已经在三层交换机那里配置了DHCP服务,所以可以直接让他DHCP获取自己的IP地址,在Wireless里设置SSID,安全性等参数,我设置了SSID为AA,WPA2-PSK密码为12345678。 4.5 配置终端设备 按照所分配的IP地址为其设置IP即可,也可以选择DHCP服务进行自动获取IP地址。 五、路由器或交换机配置的代码 5.1 配置各部门的交换机器(以非业务部门为例的vlan10为例) Switch(config)#vlan 10 Switch(config)#int fa0/1 Switch(config-if)#switchport mode trunk Switch(config-if)#int ra fa0/2 -14 Switch(config-if-range)#switchport mode access Switch(config-if-range)#switchport access vlan 105.2 为Vlan配置DHCP(以vlan100为例) Switch(config)#int vlan100 Switch(config-if)#ip routing Switch(config)#ip dhcp pool vlan100dhcppool Switch(dhcp-config)#default-router 192.168.100.1 Switch(dhcp-config)#network 192.168.100.10 255.255.255.0 Switch(dhcp-config)#dns-server 192.168.100.3 Switch(dhcp-config)#exit Switch(config)#ip dhcp excluded-address 192.168.100.3 Switch(config)#ip dhcp excluded-address 192.168.100.15.3 配置三层交换机端口模式 Switch(config)#int fa0/1 Switch(config-if)#switchport mode access Switch(config-if)#switchport access vlan 100 Switch(config-if)#int fa0/2 Switch(config-if)#switchport mode trunk Switch(config-if)#int fa0/3 Switch(config-if)#switchport mode trunk Switch(config-if)#int fa0/4 Switch(config-if)#no switchport 5.4 为各个Vlan分配IP地址 Switch(config-if)#int vlan10 Switch(config-if)#ip address 192.168.10.1 255.255.255.0 Switch(config-if)#int vlan20 Switch(config-if)#ip add Switch(config-if)#ip address 192.168.20.1 255.255.255.0 Switch(config-if)#int vlan100 Switch(config-if)#ip add Switch(config-if)#ip address 192.168.100.1 255.255.255.05.5 配置路由 Switch(config)#interface fa0/4 Switch(config-if)#ip address 10.0.0.1 255.255.255.252 Switch(config)#ip route 0.0.0.0 0.0.0.0 10.0.0.25.6 配置ACL Router(config)#access-list 1 permit 192.168.10.0 0.0.0.2555.7 配置网络地址转化 Router(config)#ip nat inside source list 1 interface fa0/1 overload Router(config)#int fa0/0 Router(config-if)#ip nat inside Router(config-if)#int fa0/1 Router(config-if)#ip nat outside 六、显示最终的结果 1735557743454图片 图6-1 两个PDA设备可以与内网服务器通信 1735557750805图片 图6-2 可以共享使用内部资源 1735557759636图片 图6-3 业务部门不可访问外部网络 1735557770689图片 1735557777015图片 图6-4 配置DNS服务器后可以域名访问内外网 七、课程设计总结 经过一周的深入学习和实践,我顺利完成了小型企业局域网建设的课程设计。本次课程设计不仅加深了我对网络组网过程及方案设计的理解,也让我熟练掌握了子网划分、路由协议配置以及路由器和交换机的基本配置等关键技能。 本次课程设计的核心目标是构建一个高效、安全的小型企业网络,并实现资源共享、通信服务以及网络划分和路由配置等功能。通过综合运用VLAN(虚拟局域网)技术和NAT(网络地址转换)技术,我成功实现了这一目标。 在课程设计的初期,我首先进行了需求分析,明确了小型企业网络的建设需求。基于这些需求,我进行了网络结构划分,将整个内部网络划分为公司总服务器、业务部门、非业务部门和外部网络四个主要部分。这一划分不仅有助于提升网络的安全性和稳定性,也为后续的网络配置和管理提供了便利。 在设备选择方面,我充分考虑了小型企业的实际需求和经济条件,选择了三层交换机作为网络核心设备,以实现各个子网之间的互通和节约资金。同时,我也为业务部门和非业务部门分别选择了交换机和无线路由器,以满足其不同的网络接入需求。 在外部网络接入方面,我了解了PPPOE、ADSL宽带接入或公网IP等接入方式,并模拟选择了111.111.111.1/24作为外部网络地址。这一选择为小型企业提供了高速、稳定的网络连接,并为其与外部网络进行信息共享和业务协同提供了有力支持。 在本次课程设计中,我遇到了多个技术难点和挑战。其中,子网划分和路由协议配置是最为关键的两个环节。 子网划分是构建小型企业网络的基础,它涉及到IP地址的规划和分配。在课程设计过程中,我根据各个部门的实际需求和网络设备的性能特点,进行了合理的子网划分。这一步骤不仅有助于提升网络的传输效率和安全性,也为后续的网络配置和管理提供了重要依据。 路由协议配置则是实现网络互通的关键。在本次课程设计中,我选择了适当的路由协议,并进行了详细的配置。通过配置路由协议,我成功实现了各个子网之间的互通和访问控制,为小型企业网络的正常运行提供了有力保障。 此外,在课程设计过程中,我还遇到了线材选取、布线设计以及模拟组网等多个技术难点。针对这些问题,我进行了深入研究和实践,最终成功解决了这些问题,并构建了一个高效、安全的小型企业网络。 在本次课程设计中,我尝试将VLAN技术和NAT技术相结合,以实现小型企业网络的高效和安全运行,为后续的网络扩展和升级提供了便利。 在课程设计的总结阶段,我还对课程设计过程中的经验和教训进行了深入反思和总结。通过这一过程,我不仅加深了对网络组网和方案设计的理解,也提高了自己的实践能力和综合素质。 通过本次课程设计,我深刻体会到了网络组网和方案设计的重要性和复杂性。在课程设计过程中,我不仅掌握了子网划分、路由协议配置以及路由器和交换机的基本配置等关键技能,还学会了如何运用所学知识解决实际问题。 展望未来,我将继续深入学习网络技术和组网方案设计的相关知识,不断提升自己的实践能力和综合素质。同时,我也将积极参与各类实践活动和项目合作,以拓展自己的视野和提升自己的综合能力。 总之,本次课程设计是一次非常宝贵的学习和实践经历。通过这一过程的锻炼和洗礼,掌握了关键的网络技术和组网方案设计技能,这些收获将为我今后的学习和工作提供有力支持和帮助。